

エグゼクティブサマリー
現代の科学研究では、人工知能(AI)が変革の推進力として台頭し、研究者が研究を概念化、実施、検証する方法が根本的に変わってきています。計算能力、高度なアルゴリズム、膨大なデータセットを収束するAIは、理論上の可能性だったものが、今や科学分野における実用的な必需品となっています。
この変革により、科学の進歩を制限してきたいくつかの長年の課題、すなわち、ゲノミクス、医学、材料科学などの分野で生成される膨大な量のデータ、新薬発見などのプロセスにかかる膨大な時間とコスト、仮説生成における認知的限界に対処できるようになりました。AIは、これらの課題を克服し、多くの科学分野でより迅速なブレークスルーを発見するための、新しい有望な道筋を提供します。
たとえば、生物医学の分野では、AIはタンパク質構造予測に革命をもたらし、創薬プロセスを加速し、個別化医療の可能性を広げました。同様に、材料科学の分野でもAIは新規材料の発見を加速させています。これらの進歩は、自動運転の実験室や逆設計フレームワークへの道を開き、科学的な方法そのものを変えています。AIは、リアルタイムの実験調整を可能にし、無駄とコストを削減しながら収率と効率を向上させることで、非常に高度なプロセス最適化を実現しています。
弊社では、科学的発見におけるこれらの技術的進歩の実現と影響を理解するために、人間がキュレーションした最大の科学情報リポジトリであるCASコンテンツのコレクションTMの定量分析を行い、2015~2025年におけるCASコンテンツのコレクションから31万件を超える学術論文と特許を体系的に分析し、高度な分析技術を使用してAI関連の出版物とそれに関連する方法論、機関、研究分野を特定しました。
弊社の研究では、生物医科学と材料科学という2つの重要な分野を深く分析して、科学分野全体におけるAI手法の分布を調査しました。これらの分析では、主要な概念、AI手法の共起パターン、および注目すべき物質クラスについて詳細に説明しています。さらに、産業プロセスの最適化と新しい応用におけるAIの役割も調査しました。
これらの調査結果は、科学研究におけるAI統合の現状と道筋に関する重要な洞察を提供し、研究者、機関、政策立案者にとって、技術採用パターンを理解し、コラボレーション機会を特定し、将来のAI投資と研究の方向性に関する情報に基づいた戦略的決定を行うための貴重な指針となります。
科学におけるAIモデルの現状
特定のモデルが選択される背景とその影響を理解するために、論文や対応特許を含め、AIベースの手法を取り入れた科学出版物の包括的な分析を行いました。全体の現状を可視化すると、より多くのモデルや機能が開発されるにつれて、科学分野全体でこれらの技術の統合が進んでいることが明らかになりました(図1参照)。
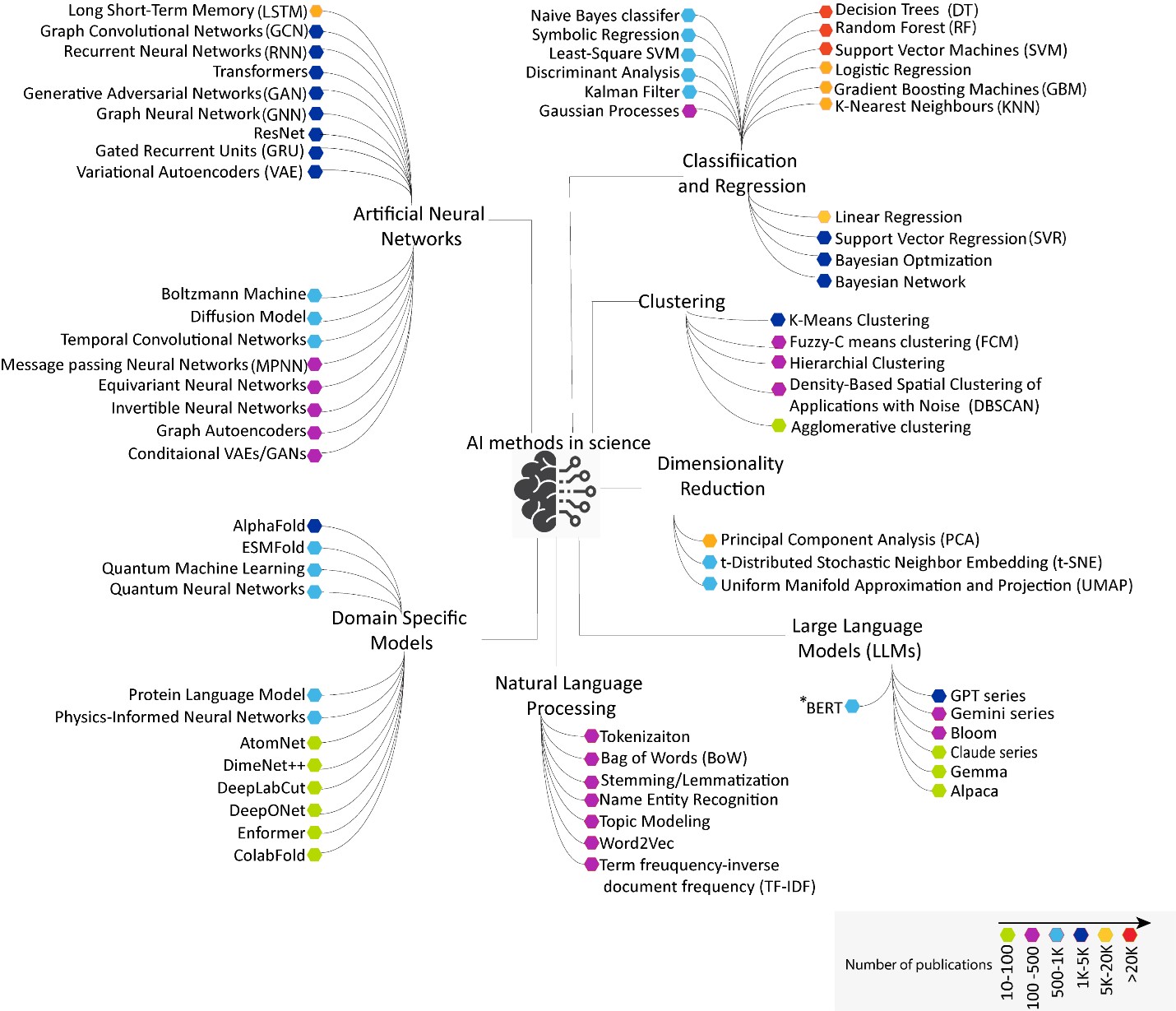
この可視化の主なブランチは以下のとおりです。
分類、回帰、クラスタリングモデル
分類モデルは、個別のラベルやカテゴリーを予測するために設計されており、高次元データの処理と解釈可能な結果を提供するのに特に効果的です。一般的なモデルには、データを再帰的にブランチに分割して結果を分類するデシジョンツリー(DT)があります。ランダムフォレスト(RF)はデシジョンツリーの助演者で、予測を平均化することでオーバーフィッティングを減らします。もう一つの一般的なモデルであるサポートベクターマシン(SVM)は、クラス間の最適な境界を見つけ出し、K近傍法(KNN)は最近傍の多数派クラスを分類します。
これらのモデルは、分光法、顕微鏡法、または既知のクラスのオミクスデータなど、カテゴリー別の結果を持つラベル付きデータセット(教師あり学習)に広く適用されています。例としては、遺伝子発現や画像データからの病気の種類の分類、物質のクラスの予測、毒性や反応性に基づいた化合物の分類などがあります。
回帰モデルは連続的な数値を予測するため、予測や最適化に理想的なモデルです。出版物で見られる回帰モデルには、線形回帰、ロジスティック回帰、サポートベクター回帰(SVR)、シンボリック回帰などがあります。これらのモデルは、実験やシミュレーションからの数値データ、またはセンサーや機器からの時系列データに適しています。その用途には、エネルギーレベル、減衰率、粒子軌道の予測、反応収率の推定、分子特性、モデリング温度、降水量、導電率、硬度、バンドギャップの予測などがあります。
クラスタリングモデルは、分類や回帰とは異なり、ラベルのないデータ内の自然なグループ化を見つけ出し、隠れた構造を明らかにして探索的分析(教師なし学習)をサポートします。これらのモデルは、画像データ、スペクトルデータ、分子データなどの高次元でラベルのないデータセットに有効です。このグループに適した科学的データには、発現プロファイルに基づく遺伝子やサンプルのグループ化や、構造データからの新しい材料ファミリーの発見など、さまざまなものがあります。
人工ニューラルネットワーク(ANN)
ANNとは、相互接続された人工ニューロンの層を通じて複雑なパターンを学習するように設計された機械学習(ML)モデルの一種です。これは、データ内の複雑で非線形な関係をモデル化するのに役立ちます。結果として、ディープラーニングの基礎を形成し、シーケンシャルデータ用の回帰型ニューラルネットワーク(RNN)、長距離依存関係をより適切にキャプチャする強化されたRNNである長・短期記憶(LSTM)、およびLSTMの簡易バージョンでありパラメータが少ないゲート付き回帰型ユニット(GRU)などの特殊なアーキテクチャを備えた現代のAIの基盤となっています。
これらのモデルは、遺伝子発現、タンパク質配列、生理学的信号、気候データ、素粒子物理学、センサーネットワークデータなどの配列データや時系列データに適しています。多くの場合、ナレッジマップ(ドメイン固有の概念とその関係を構造的に表したもの)を活用して、画像とテキストの連携を強化します。これは、視覚データ(医療画像など)とテキストによる説明(臨床メモや診断レポートなど)の間の意味的なギャップを埋めるのに役立ちます。創薬開発、精密医療、医療画像、材料発見および設計、エネルギー貯蔵、製造、品質管理などの分野で採用が急増しています。
ハイブリッド化された手法
ANNと、従来の分類、回帰、クラスタリングなどのMLモデルとの比較は、単にどちらが優れているかを決めるのではなく、互いの補完的な役割を理解することが重要です。ANNは、データが複雑かつ非構造化されている場合、トレーニングデータセットが大きい場合、および表現学習が必要な場合に主に使用されます。逆に、データ量が少なく、研究問題に厳密な解釈可能性が求められ、入力に十分に理解された統計的関係があり、不確かさの定量化が必要な場合には、従来のMLが適しています。
ドメイン固有のモデル
ドメイン固有のモデルは、出版数は少ないものの、タンパク質構造予測において実験値に近い精度を達成したディープラーニングアプローチであるAlphaFoldのような、画期的な研究が含まれています。ESMFoldは、タンパク質言語モデリングを直接活用して、単一のタンパク質配列から高品質の構造予測を直接生成する、もう1つの興味深いモデルです。
自然言語処理 (NLP)
NLPは、ヒトの言語を分析、理解、解釈、生成するために使用されます。これには、アルゴリズムで処理できるトークン化(テキストをトークンと呼ばれる小さな単位、通常は単語またはサブワードに分解する)などのタスクが含まれます。テキストを表現する一般的な方法には、文法と語順を無視して、単語の頻度に基づいてテキストを数値ベクトルに変換するBag of Words(BoW)モデルがあります。もう1つの重要な技術は、テキスト内の人名、組織名、地名などのエンティティを識別して分類する固有表現抽出(NER)です。
生物医学テキストマイニングおよび知識抽出におけるNLPモデルの応用範囲は広く、生物医学文献で事前トレーニングされた特殊な言語モデル(BioBERT、BioGPTなど)および電子カルテ(EHR)分析から、臨床記録からの疾患特性の自動抽出や言語モデルを使用した新しい候補薬の作成まで、多岐にわたります。材料科学および化学では、NLPは合成プロトコル抽出、材料特性予測、知識ベースの構築、逆設計に使用されています。
大規模言語モデル(LLM)
この革新的なAIシステムはNLPに革命をもたらし、科学分野全体で広範な応用が見出されています。LLMは、膨大な量のテキストデータでトレーニングされ、言語の統計パターンを学習したニューラルネットワークベースのシステムで、情報抽出、要約、ナレッジグラフの構築、ドメイン間統合、および生成用途に使用されています。
広く採用されているLLMには、ChatGPT、GPT-3.5、GPT-4を駆動するGenerative Pre-Trained Transformer(GPT)があります。Bidirectional Encoder Representations from Transformers(BERT)は、双方向コンテキスト理解と、質問応答および感情分析における優れたパフォーマンスにより、学術界で強い関心を集めており、言語モデルの中では依然としてトップクラスの地位にあります。
多言語モデルであるBLOOMは、研究環境に大きく貢献するものとして登場しました。Google DeepMindが開発したGEMINI、Meta AIのLLAMA、Anthropicが開発したClaudeなどの新しいモデルも人気が高まっています。2023~2025年に登場した最新世代のモデルであるGemma、Falcon、Mistral、Qwen、DeepSeekは、将来の発展に大きな期待が寄せられています。
ChemLLM、PharmaGPT、MatSciBERTなど、化学、生命科学、材料科学に特化したLLMの登場も大きなインパクトがありました。
AIの科学への影響を示す出版傾向
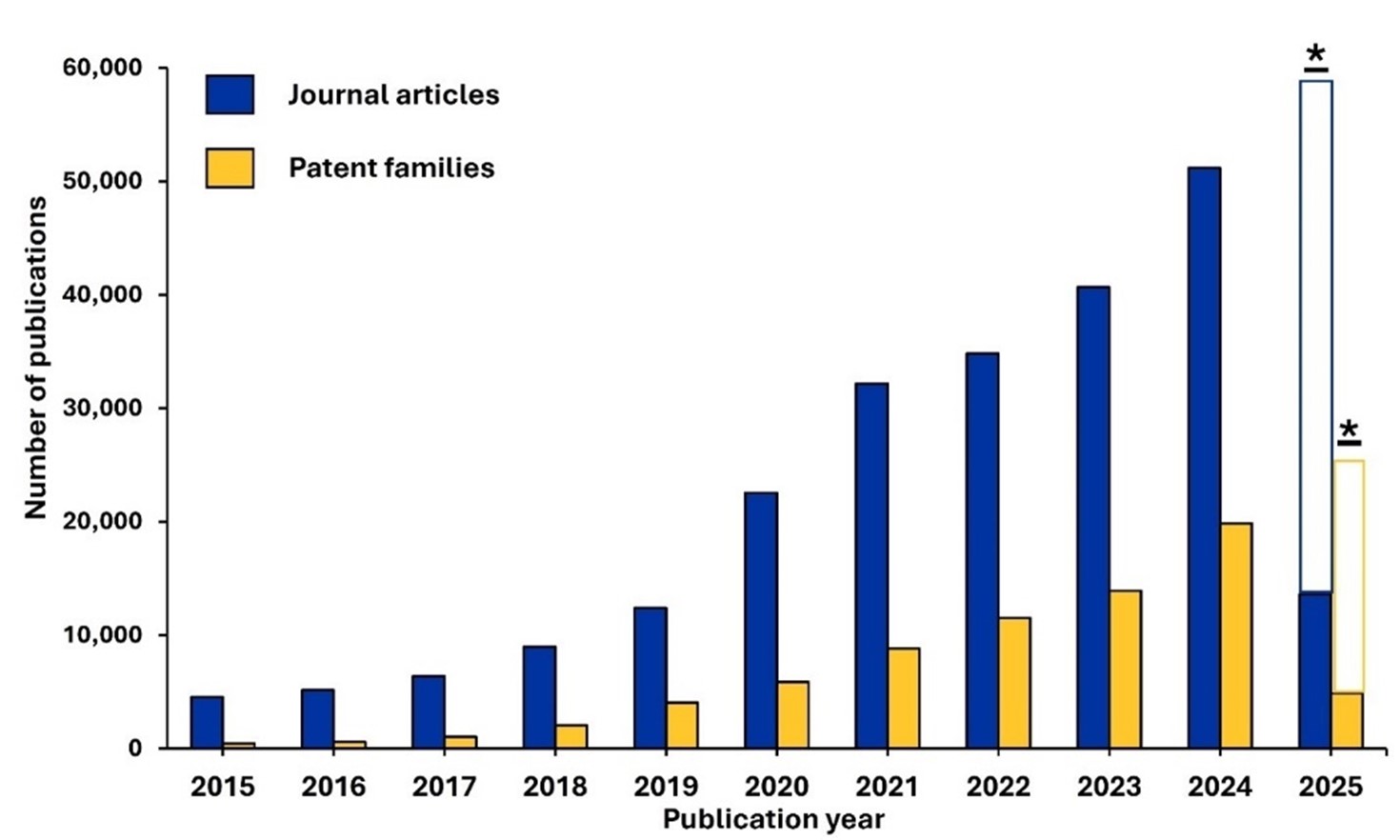
前述のとおり、弊社は2015~2025年のCASコンテンツのコレクションの科学研究におけるAIに関連する310,000件の文献を分析しました。その結果、期間全体を通して着実な成長が見られ、最近5年間では非常に顕著な成長が見られました(図2参照)。対応特許の増加は、AIがもはや新興技術などではなく、さまざまな業界で不可欠な研究ツールへと進化していることを強く示唆しています。
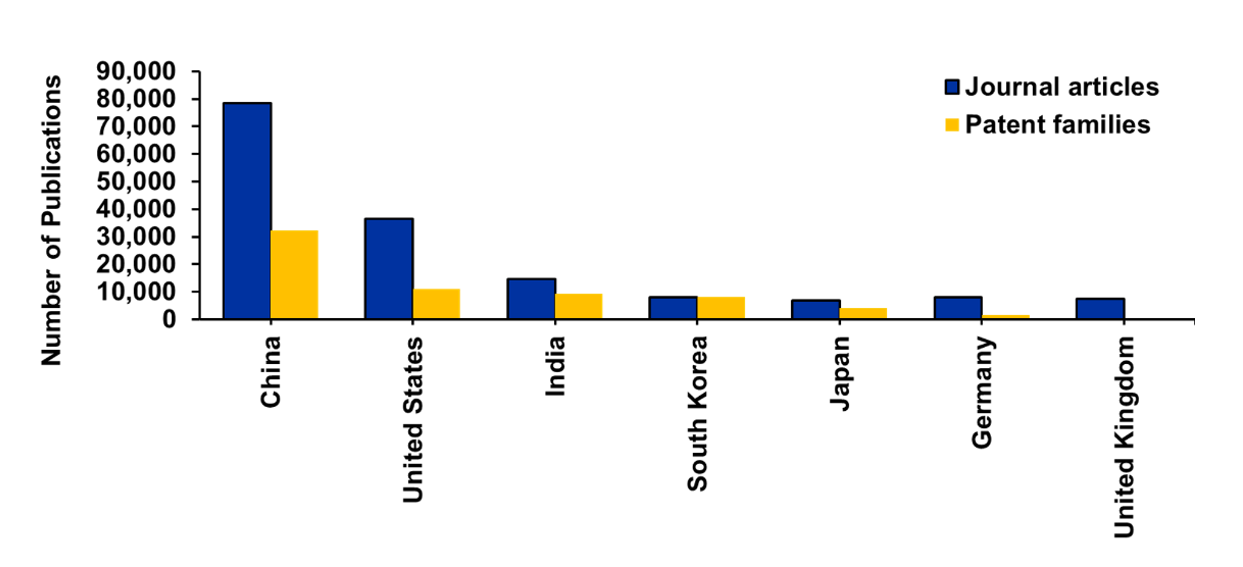
- 国/地域および組織別の分布:中国が出版物数(論文および特許)でリードしていますが、米国、インド、韓国、日本も出版物数で着実な成長を示しています(図3参照)。特許に関しては、この分野におけるグローバル特許の75%以上を中国とインドが占めており、特許申請数上位15機関は中国とインドの機関です。中国の大学は論文発表量で優位に立っており、ほとんどの大学の平均引用数は10~20となっています。対照的に、MITとスタンフォード大学は、それぞれ32と66という大幅に高い平均引用数を誇っています。これは、中国は量では勝っているものの、AI分野の学術論文の質と影響力の面では米国の大学にリードを許していることを示唆しています。
- 特定の出版物における分布:弊社は、AIベースの科学研究を発表する主要な科学文献の出版量と引用インパクトを分析しました。出版物はScientific Reports、Applied Sciences、およびPLoS Oneが多くなっています。しかし、論文あたりの平均引用数を考慮すると、Proceedings of the National Academy of Sciences(PNAS)が際立っており、出版量は比較的少ないにもかかわらず、1回の出版あたり約50件の引用数と、並外れた影響力を示しています。その他、Journal of Chemical Information and Modelling(JCIM)、Bioinformatics、およびNature Communicationsなどの文献も、平均引用数が顕著に高く、他の文献が膨大な量の論文を掲載しても、それを大きく上回っています。このパターンは、Scientific Reportsのような広範囲の分野を扱う文献が最も多くのAI関連研究を発表している一方で、PNAS、JCIM、およびNature Communicationsのような専門的または権威ある文献が、より大きな科学的影響を生み出す、より影響力のある科学的研究を発表していることを示唆しています。
- 科学分野別のトレンド:多くの分野がAIの影響を大きく受けていますが、特に出版物が指数関数的に増加している分野がいくつかあります(図4参照)。
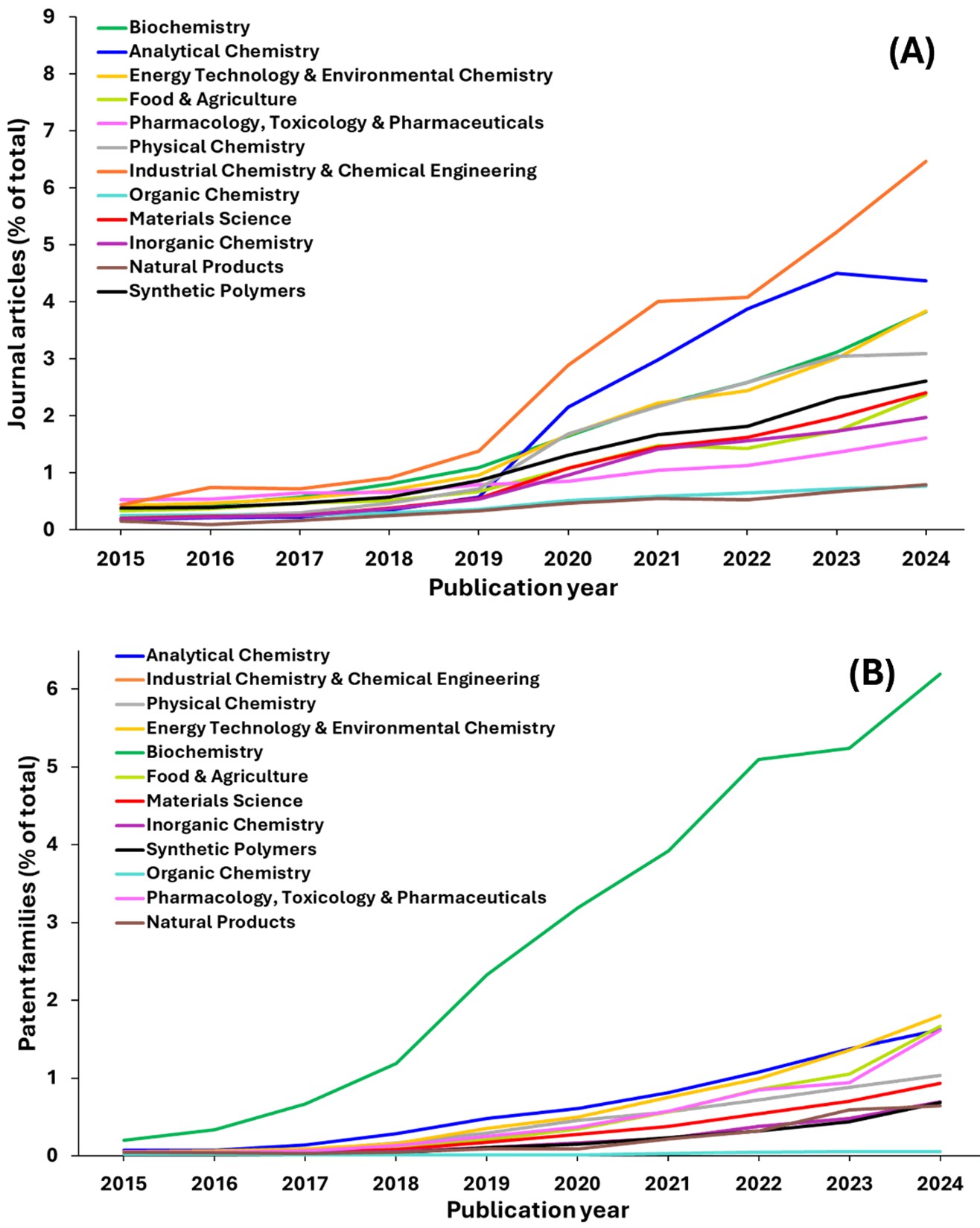
すべての分野の中で、工業化学と化学工学は学術文献において最も劇的な成長を示しており、2024年には全体の約8%に達しています。この並外れた成長は、この分野の製造、プロセス最適化、産業イノベーションへの幅広い応用と、持続可能な産業プロセスやグリーンケミストリーソリューションの開発における重要な役割を反映していると考えられます。
分析化学は、学術文献において2番目に急成長している分野として存在感を強めています。図4では、2019年以降、紺色の線が堅調な成長を示しています。この力強い成長パターンは、化学のあらゆる領域におけるこの分野の根本的な重要性と、複数の分野にわたって研究を支える新しい測定技術、機器、分析方法の開発における役割を物語っています。
エネルギー技術および環境化学は堅調な成長を示しており、最も急成長している分野の中で生化学と並んで第3位にランクされています。これは、気候変動、環境の持続可能性の課題、新たな問題に対するグローバルな緊急の取り組みを反映しています。
物理化学、薬理学、毒物学および薬学、有機化学、無機化学、天然物、合成ポリマーなどの残りの分野では、いずれも出版量が緩やかながらも着実に増加しています。これらの分野は、科学的な基本原理が確立されているものの、継続的な科学研究によって漸進的な進歩と改良がもたらされる、成熟した科学研究領域といえます。
対応特許のデータは、学術成果の均一な増加ではなく、非常に多様で集中したイノベーションパターンを見せており、学術文献とは著しく異なる状況を示しています。この対比は、学術研究の生産性と商業的に実行可能なイノベーションの根本的な違いを浮き彫りにしています。どの科学的進歩が特許を取れる知的財産に移行できるかを決定する上で、市場の力、実用的な応用、経済的インセンティブが決定的な役割を果たします。
特許の中で、生化学は指数関数的な成長を示しており、2024年までに約8%に達し、他のすべての分野を完全に凌駕しています。生化学の特許状況は生物医学的手法によって占められており、分子科学と高度な医療技術を融合させるイノベーションによって形作られています。主な分野には、疾患検出、医療画像、ウェアラブルモニタリング、臨床意思決定サポートなどがあり、いずれも生化学マーカーを活用しています。生化学はまた、神経学的インターフェース、ゲノミクス、バイオマーカーの発見、信号処理、外科的指導、および生物医学製造の進歩を促進し、現代の生物医学イノベーションにおける中心的な役割を果たしています。この劇的な特許活動は、ライフサイエンス研究全般に対する強い商業的関心と投資を反映しており、さらに、COVIDパンデミックへの対応として商業研究に多額の資金が提供されたことが後押しとなりました。
弊社の分析によると、AI関連の出版物の大部分は生物医学研究と材料科学に関連していることがわかりました。そこで、これらの主要な研究分野について詳細な分析を行いました。これらの分野はデータセットの大部分を占め、AIの採用が急速に進み、年間成長率が顕著で、引用による影響が大きく、科学的な関連性が示されています。
生物医学研究におけるAIモデルの応用
概要
生物医学研究は、複雑さとコストの面で継続的な課題に直面していますが、AIの登場により、それらの課題に対処できるようになりました。たとえば、複雑なタンパク質構造と相互作用の解読、医薬品開発に伴う高コストと失敗率、多因子疾患のメカニズムの複雑さの理解などは、どれもAIベースのアプローチの出番です。
この分析の背後にある理論的根拠は、主要な概念を特定するための客観的な指標として文献の頻度を使用し、最も重要な研究分野を代表的に抽出することでした。具体的には、生物医学分野においていくつかのAI/ML手法を使用して、大きな科学的関心と研究投資を生み出した概念を特定しました(図5参照)。
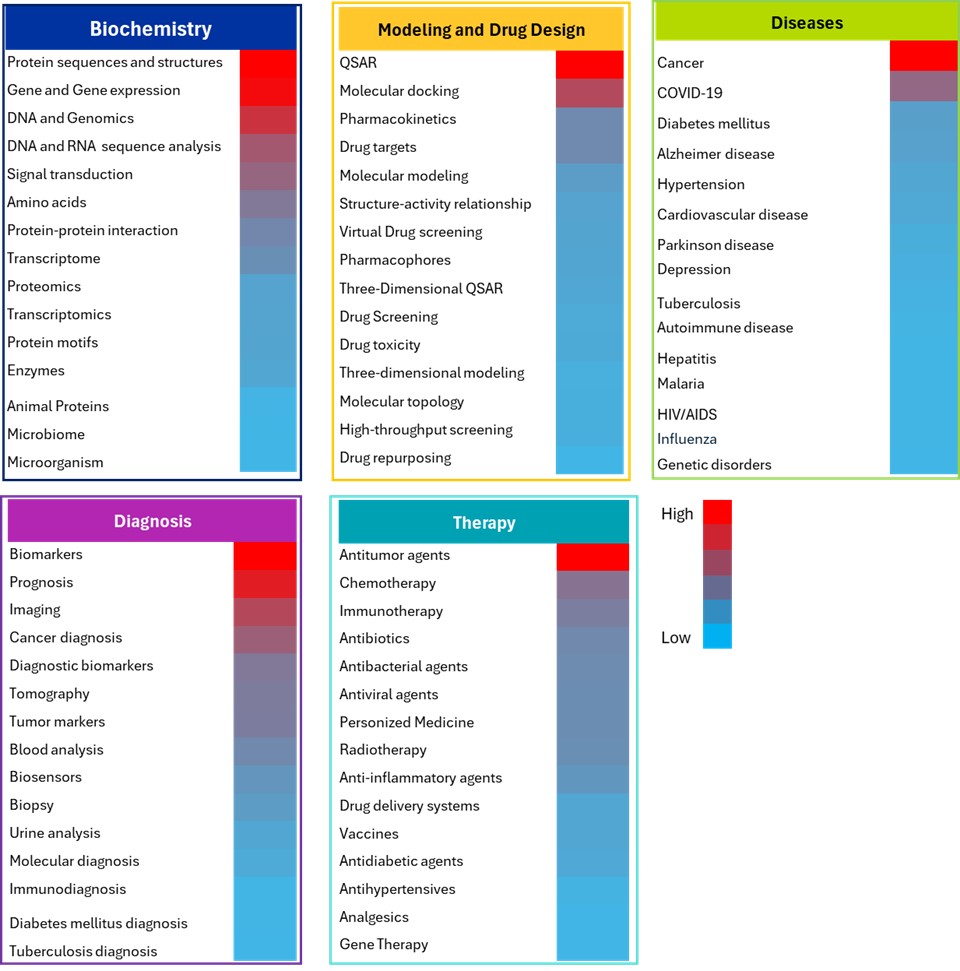
生化学の領域では、タンパク質配列と構造、遺伝子と遺伝子発現、DNA/ゲノミクスが、多様な機械学習アプローチを活用して最も広範に研究されている概念として浮上しています。MLモデルは、特にタンパク質階層や遺伝子調節ネットワークのような複雑なシステムにおいて、データの豊富さと標準化により、これらの分野で多用されています。MLは、配列-機能マッピング、タンパク質ファミリーの分類、ドメイン予測、構造-機能解析、腫瘍の特徴の選択、がんにおける遺伝子相互作用予測、腫瘍学におけるパターン発現による遺伝子のクラスタリングなどのタスクに秀でており、同時に測定された数千の遺伝子を含む高次元発現データ、遺伝子と表現型の間の複雑な非線形関係、遺伝子制御ネットワークの階層的構造を活用しています。
AlphaFoldやBERTなどの高度なMLモデルは、アミノ酸配列と進化パターンから学習して3Dフォールディングと機能ドメインを予測することにより、タンパク質構造の予測に使用されます。これらのモデルは、複雑な空間関係や長距離依存関係を持つ連続的な入力を効果的に処理します。
モデリングと薬剤設計の分野では、QSARモデリングが主流です。これは、ML手法を使用して化学構造から分子記述子(つまり物理化学的特性、フィンガープリント)を抽出し、教師あり学習アプローチを通じて生物活性と毒性エンドポイントを予測します。これらの手法は、機能豊富な分子記述子、構造活性相関、回帰タスクに適した定量的エンドポイントを備えていることが特長です。
2番目によく使用される概念である分子結合法では、3D構造データと分子グラフに対してディープラーニングアプローチ(CNNおよびGNN)を使用して、空間コンフォメーション、エネルギーランドスケープ、分子相互作用を活用し、タンパク質-リガンド結合ポーズと親和性を予測します。次点の重点分野は薬物動態学で、MLを使用して分子記述子、生理学的パラメータ、時系列データから学習し、ADMET特性(吸収、分布、代謝、排泄、毒性)と薬物クリアランス率を予測します。
バイオマーカーは診断領域で主流を占めており、ML手法によって高次元のゲノミクス、プロテオミクス、メタボロミクスのデータが分析され、特徴選択と分類を通じて健常対照群から疾患状態を区別する明確な分子署名が特定されます。AI手法は予後研究にも使用されており、患者の臨床データや治療履歴を分析し、生存時間や疾患進行を生存分析技術で予測します。
医療画像には、X線、CT、MRIのデータと、ディープラーニング手法に最適な構造化された空間情報が含まれています。CNNは、自動パターン認識を通じて腫瘍検出、骨折識別、疾患分類、病理状態の分析のために放射線画像解析に広く用いられています。ディープラーニングがマルチスケールの特徴を抽出する能力やセグメンテーションタスクを実行する能力は、画像処理分野にも有益です。特にがん診断においては、腫瘍の検出、分類、悪性度評価、リスク予測を支援します。
疾患領域では、がん研究が最も注目され、データの種類に基づいてさまざまなMLモデルが適用されました。ゲノムおよびトランスクリプトームデータは通常、がんのサブタイプ分類と治療予測のために、RFおよびSVMモデルを使用して解析されます。これらの解析は、多様な分子層を捉えるマルチオミクスデータの統合や、異種の腫瘍微小環境の複雑さをモデル化することから恩恵を得ています。
糖尿病研究では、経時的なモニタリングデータ、生活習慣要因と遺伝子の複雑な相互作用、血糖値の時系列予測問題を活用し、糖尿病合併症の予測や治療プロトコルの最適化のために様々なアルゴリズムが用いられています。アルツハイマー病では、ランダムフォレスト(RF)やサポートベクターマシン(SVM)モデルが広く使われており、神経心理学的検査のスコアやバイオマーカー(アミロイドベータ、タウタンパク質)、人口統計学的データを解析して、健常者と軽度認知障害の患者を分類し、早期予測を行っています。
治療領域では、抗腫瘍剤が最も研究の注目を集めており、分子記述子と化学的特性を解析して、潜在的な抗がん活性を持つ化合物を特定するために、薬剤スクリーニングと活性予測にML手法が活用されています。化学療法では、患者の臨床データ、遺伝子プロファイル、腫瘍特性を分析し、治療反応や毒性を予測することで、薬剤の選択と投与プロトコルの個別化を実現しています。同様に、これらのモデルは患者の免疫プロファイル、腫瘍変異負荷、バイオマーカー発現を分析し、免疫相互作用の複雑性と時間的動態に対応しながら、反応を予測し治療成果を最適化することで、免疫療法をサポートしています。
AIモデルと生物医学概念の共起
私たちの分析では、生物医学的概念とさまざまなAI/ML手法との共起パターンを調査し、5つの領域にわたる戦略的な応用を明らかにしています(図6を参照)。
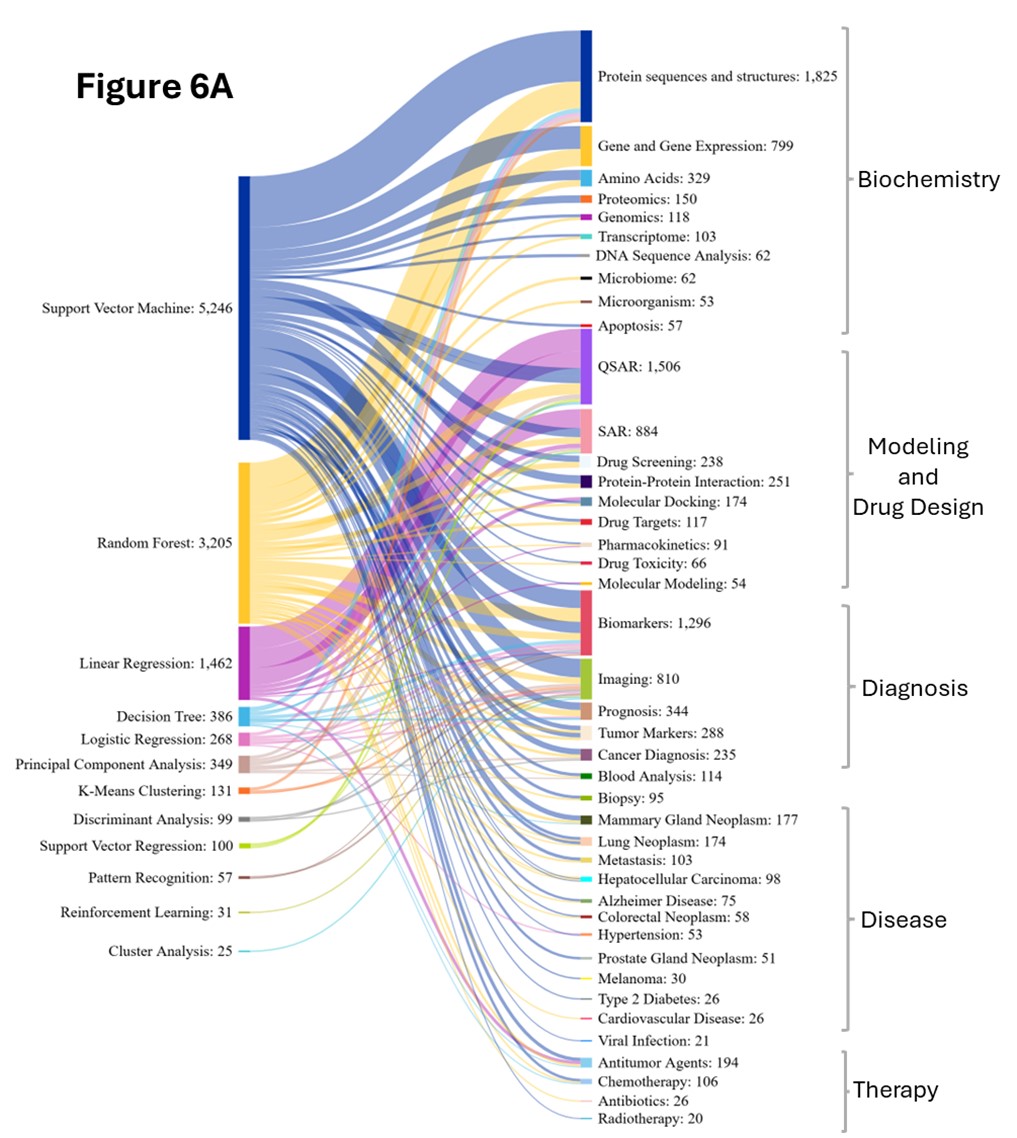

ランダムフォレスト(RF)は、バイオメディカル研究において支配的なAI手法として台頭し、2つの期間の間に顕著な成長を示し、サポートベクターマシン(SVM)を追い抜きました。RFは、生体医科学のすべての領域、特に生化学、診断、および疾病関連の研究において、概念との強い共起を示しています。RFは、アミノ酸組成、配列モチーフ、および物理化学的特性を解析することでタンパク質の機能予測と分類を行い、タンパク質を機能ファミリーに分類するために使用されます。バイオマーカーの発見では、RFは高次元のゲノミクス、プロテオミクス、メタボロミクスのデータを分析するために使用されます。
サポートベクターマシン(SVM)は、期間を通じて着実に成長しつつ、タンパク質、遺伝子発現、DNAおよびゲノミクス、バイオマーカー、予後、医用画像、がん研究において大きな存在感を維持しています。タンパク質研究において、SVMはアミノ酸配列、構造的特徴、および物理化学的特性を分析して、タンパク質の分類と機能注釈に使用されます。また、細胞内の局在を予測し、カーネルベースの高次元特徴空間マッピングを使用して酵素クラスを識別します。
遺伝子発現では、SVMは特定の生化学的プロセスに関与する遺伝子を同定し、代謝経路を分類し、さまざまな生化学的条件と細胞状態にわたる遺伝子の発現パターンに基づいて酵素をコードする遺伝子を予測します。ゲノム変異体の分類では、SVMはDNA配列の特徴と注釈を処理して、病原性の変異と良性の変異を区別し、ヌクレオチドパターンとゲノムコンテキストの高次元特徴分析を通じて疾患関連ゲノム領域を特定します。
バイオマーカー研究において、SVMは複数のバイオマーカーを統合して予測モデルを構築し、診断、治療反応、病気の進行リスク評価、そして個別化医療のための患者の層別化を支援しています。がん研究では、SVMはがん組織と正常組織の識別、がんの種類の分類、さらに特定のがんにおける分子サブタイプの同定に使用されています。また、臨床パラメータ、バイオマーカープロファイル、ゲノム情報を統合して予後や治療効果、薬剤耐性パターン、再発リスクの予測にも応用されています。図6Bは、SVMがQSARやSARモデリングにおいて依然として強みを持つ一方で、後期にはRFに比べてタンパク質解析への関連性が弱まったことを示しています。
ロジスティック回帰(LR)は、生物医研究で広く使用されている解釈可能な統計手法であり、タンパク質、遺伝子発現、バイオマーカー、予後、医用画像、がん、COVID-19などの重要な概念とよく共起します。タンパク質機能予測では、LRはアミノ酸組成、配列特徴、構造特性を分析して、タンパク質を機能的または構造的カテゴリに分類します。このモデルの主な利点は、分類決定に対する各特徴の相対的な寄与を示す解釈可能な係数を提供することで、研究者はどのアミノ酸特性または構造的特徴が予測に最も強く影響するかを特定できます。
この解釈可能性は遺伝子発現分類においても同様に価値があり、LRは差次的に発現する遺伝子を識別するのに役立ちます。バイオマーカーの検証と診断では、LRモデルは病気/健康、反応者/非反応者などのバイナリ結果を予測し、診断の意思決定に臨床的に意味のあるオッズ比を提供します。予後モデリングでは、LRは臨床パラメータ、バイオマーカーのプロファイル、患者の人口統計を評価して、死亡率/生存率、病気の再発/寛解、予後良好/不良などの結果を予測する同様のバイナリ結果予測を使用します。
LRは、併存疾患、バイタルサイン、バイオマーカーを統合してCOVID-19の診断、重症度予測、死亡率の予測に使用され、リスク層別化と臨床意思決定をサポートします。これらの多様な応用は、LRと中核的な生物医学研究テーマとの強力な整合性を強調し、LRを解釈可能で臨床的に関連性のあるモデリングの基盤ツールにしています。図6Bは、ロジスティック回帰の適応性の増加を示しています。これはおそらく、連続予測に限定される線形回帰とは異なり、マルチクラス分類と確率ベースの出力が可能であるためです。
図6Bに見られるように、2020年から2024年の期間には、 AlphaFoldなど、以前にはほとんど存在しなかった特殊なディープラーニング手法が登場しました。この期間には、分子間相互作用のモデリングのためのグラフニューラルネットワーク(GNN)の使用、合成データ生成のためのグラフ敵対的ネットワーク(GAN)の使用、そしてイメージングアプリケーションや診断上の課題のためのパターン認識の使用も急増しました。
近年のもう一つの大きな変化は、臨床レポートのマイニングや生物医学テキストの分析のためにBERTのようなモデルの台頭によって強調される、NLP技術の生物医学研究への統合です。この専門分野は、汎用的なAI手法の適用を超えて、特定の生物医学的課題に向けた特化したアプローチの開発へと、この分野が成熟したことを反映しています。
リサーチの優先順位は、この2つの期間の間で大きく変化しました。蛋白質配列および構造分析と遺伝子発現解析は、2020年から2024年にかけて大幅に増加しました(図6B)。バイオマーカーの発見とイメージングアプリケーションも劇的な成長を遂げ、疾患特有の研究も大幅に拡大し、COVID-19が主要な焦点として浮上し、がん研究は複数のサブタイプに多様化しました。
生物医学研究における物質
この比較により、十分に研究されていない治療機会に関する戦略的な洞察が得られ、科学的発見と臨床応用のギャップを埋めるための研究投資の増加や革新的なアプローチから恩恵を受ける可能性のある物質クラスが明らかになります(図7を参照)。「物質クラス」とは、治療への応用の可能性が認められているCASインデックスの物質のカテゴリーを指します。
低分子薬は引き続き医薬品研究開発の中心であり、AIテクノロジーがその発見を加速させています。MLベースの仮想スクリーニング、薬物動態予測のためのQSARモデリング、合成経路を最適化するディープラーニングシステムが、このプロセスに不可欠なものとなっています。これらの革新は、確立された合成経路、十分に特徴付けられた薬物動態、経口バイオアベイラビリティ、費用対効果の高い製造など、低分子固有の利点に基づいています。
タンパク質/ペプチド治療薬は、2番目にリサーチされているカテゴリーです。AlphaFoldのようなツールはタンパク質構造予測に革命をもたらし、糖尿病のインスリン、脳卒中の組織プラスミノーゲン活性化因子、がんや自己免疫疾患のモノクローナル抗体などの治療用タンパク質の設計と最適化を可能にしました。MLモデルは、タンパク質間の相互作用を予測し、ペプチドの安定性を最適化することで、この分野をさらに強化します。
塩類化合物や塩類は、溶解度、バイオアベイラビリティ、安定性を予測するAIを活用した製剤最適化アルゴリズムの恩恵を受けており、これは医薬品の製剤やバイオアベイラビリティの最適化の重要性を反映しています。ポリマーは多くの場合、重要な治療用ドラッグデリバリーシステムとして機能しますが、AIによって設計されたナノ粒子製剤、MLによるハイドロゲル特性の最適化、標的薬物送達の予測モデリングといった技術で強化されており、治療効果や組織選択性の向上に寄与しています。
配位化合物は、AIが配位子設計と金属有機構造体(MOF)の最適化を支援する、もう一つの有望なクラスです。これらの化合物は、金属とリガンドの相互作用と生物活性を予測する計算化学とAIモデルによって精製されています。
材料科学におけるAIモデルの応用
概要
材料科学では、材料の組成、構造的特徴、特性の間の複雑な関係を理解し、予測することが材料発見の加速に不可欠です。関係するデータは、多くの場合、多次元、階層的、異種であり、高スループットのデータ集約型プロセスを通じて生成されます。AI、特にMLは、これらの複雑なデータセットの分析を可能にすることで、この分野に革命をもたらしています。私たちはCASコンテンツコレクションを分析して、AI手法が適用されている主要な材料科学の概念を特定し、材料の発見と特性予測におけるその重要性を評価しました(図8を参照)。
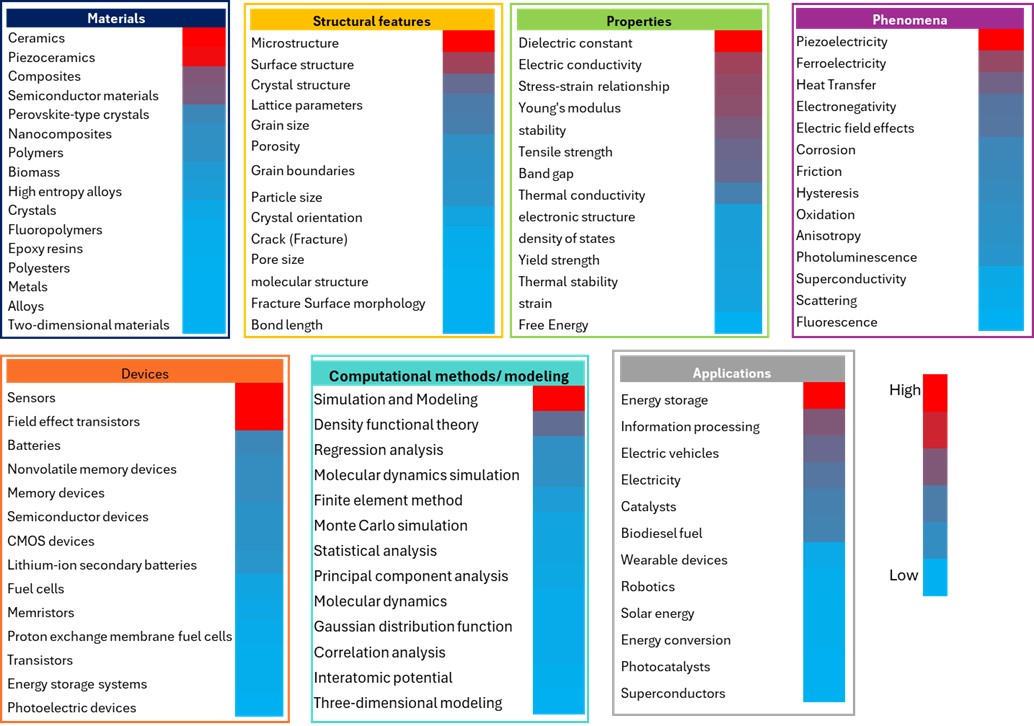
エネルギー貯蔵は、応用の中で最もAI集約的な研究分野であり、高度なバッテリー技術と持続可能なエネルギーソリューションに対する世界的なニーズを反映しています。ML技術は、バッテリー材料の革新のための強力なツールとなっており、研究者は直接的な特性予測、機械学習の可能性、逆設計という3つの主な戦略を活用しています。この分野のAI研究が集中しているのは、バッテリーシステムの複雑なマルチスケールの性質に起因しており、従来の実験的アプローチでは、材料組成、構造、電気化学的性能の間の複雑な関係を最適化することはしばしば困難です。
材料とデバイスのカテゴリーにおいて、セラミックス、圧電セラミックス、センサー、および電界効果トランジスタにおける顕著なAI活動は、これらの材料とデバイスが高度に洗練された性質を持つことを反映しています。これらの高度な材料は、複雑な構造と特性の関係を示すことが多く、機械学習アプローチの理想的な候補です。
構造的特徴では、畳み込みニューラルネットワーク(CNN)とコンピュータビジョンが、顕微鏡画像からの自動分類、セグメンテーション、特徴抽出を可能にすることで、微細構造分析に使用されていることがわかりました。これらのツールは、以前は定量化が困難だった構造と特性の相関を明らかにするのに役立っています。冶金学では、ターゲットを絞ったAIアプローチが超合金開発を前進させ、CAMEO(Closed-Loop Autonomous Materials Exploration and Optimization)のようなシステムは、AIと高スループット実験を統合することで、コンビナトリアル冶金を可能にします。さらに、3Dトモグラフィデータ用の機械学習ツールは、多孔質材料の分析を強化し、透過性や機械的強度などの特性をより正確にモデル化することを可能にしています。
誘電率と電気伝導率は特性の主要な概念であり、圧電性は現象の主要な概念です。シミュレーションとモデリングでは、計算モデリングはAIの高い採用率を示しており、これは機械学習とデータ分析タスクの自然な互換性と一致しています。
図7の紫色と混合色で表された中程度のAI活動領域は、AIの導入が加速しているものの、改善の余地がある分野です。例えば、主に青色で示される一部の材料分野における活動の低さは、科学において最も確立された基礎的な領域の一部を示しており、最も成熟した分野ほどAIの統合が最も低いという逆説的な状況を生み出しています。複合材料とポリマーは、このカテゴリーの代表的な例です。
しかし、特定の課題に対処するために、特殊なAIモデルが開発されています。モデルpolyBERTはポリマー構造を化学の言語として扱い、複雑なポリマーシステムをより効果的にモデリングできるようにします。結晶材料については、MEGNet、CGCNN、SchNetなどのモデルが結晶対称性と量子相互作用を組み込んでおり、ALIGNNは合金の特性予測に不可欠な高次の原子相互作用を捉えます。
AIモデルと材料科学概念の共起
生物医学分析と同様に、私たちは材料科学におけるAIの手法とそれに付随する概念を詳しく調べました。ランダムフォレスト(RF)、サポートベクターマシン(SVM)、勾配ブースティングマシン(GBM)、デシジョンツリー(DT)などの従来のMLモデルは、主に材料情報学でよく見られる非線形の関係を持つ高次元データにより、予測と特徴の重要性分析に広く使用されていることがわかりました(図9を参照)。
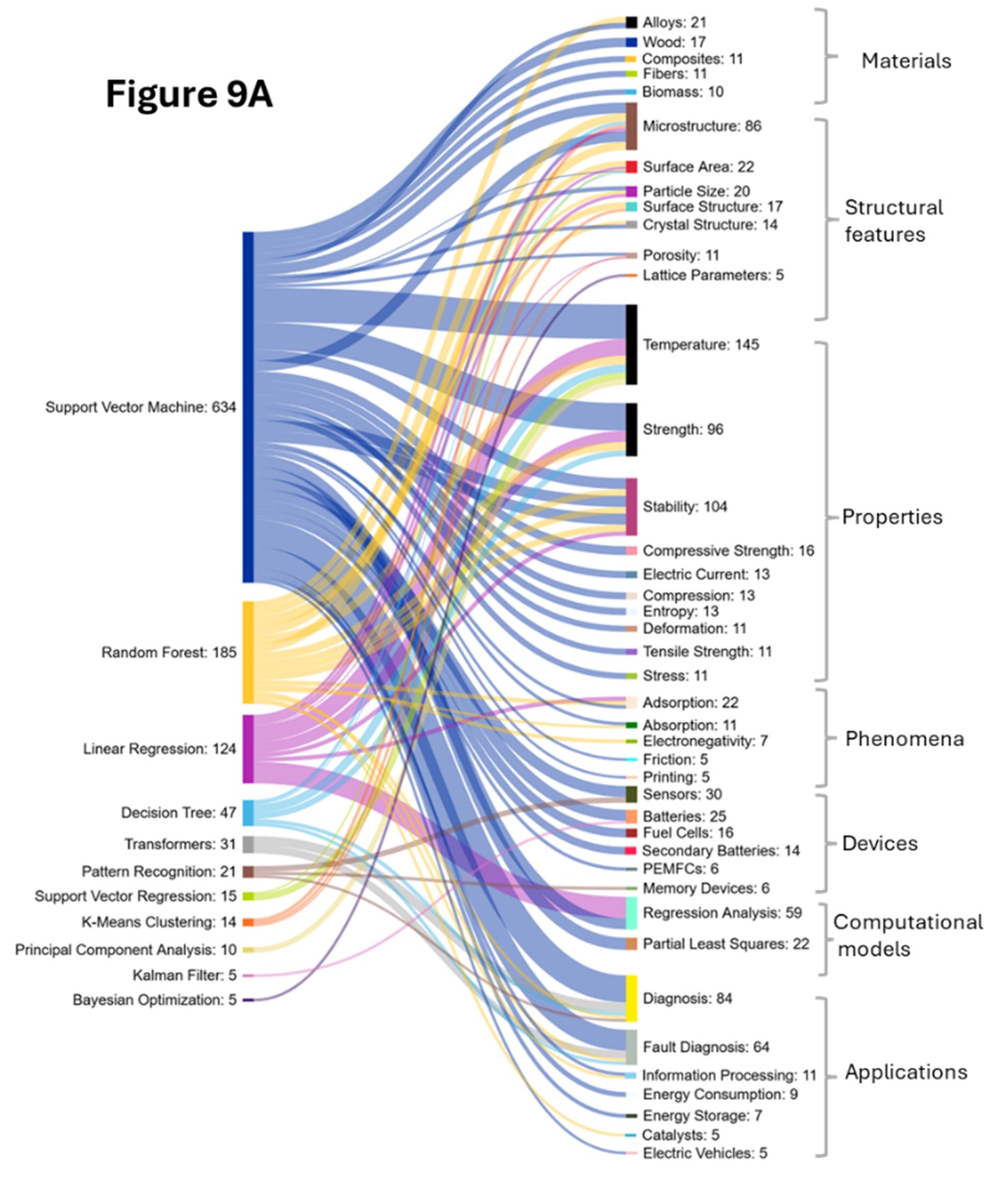
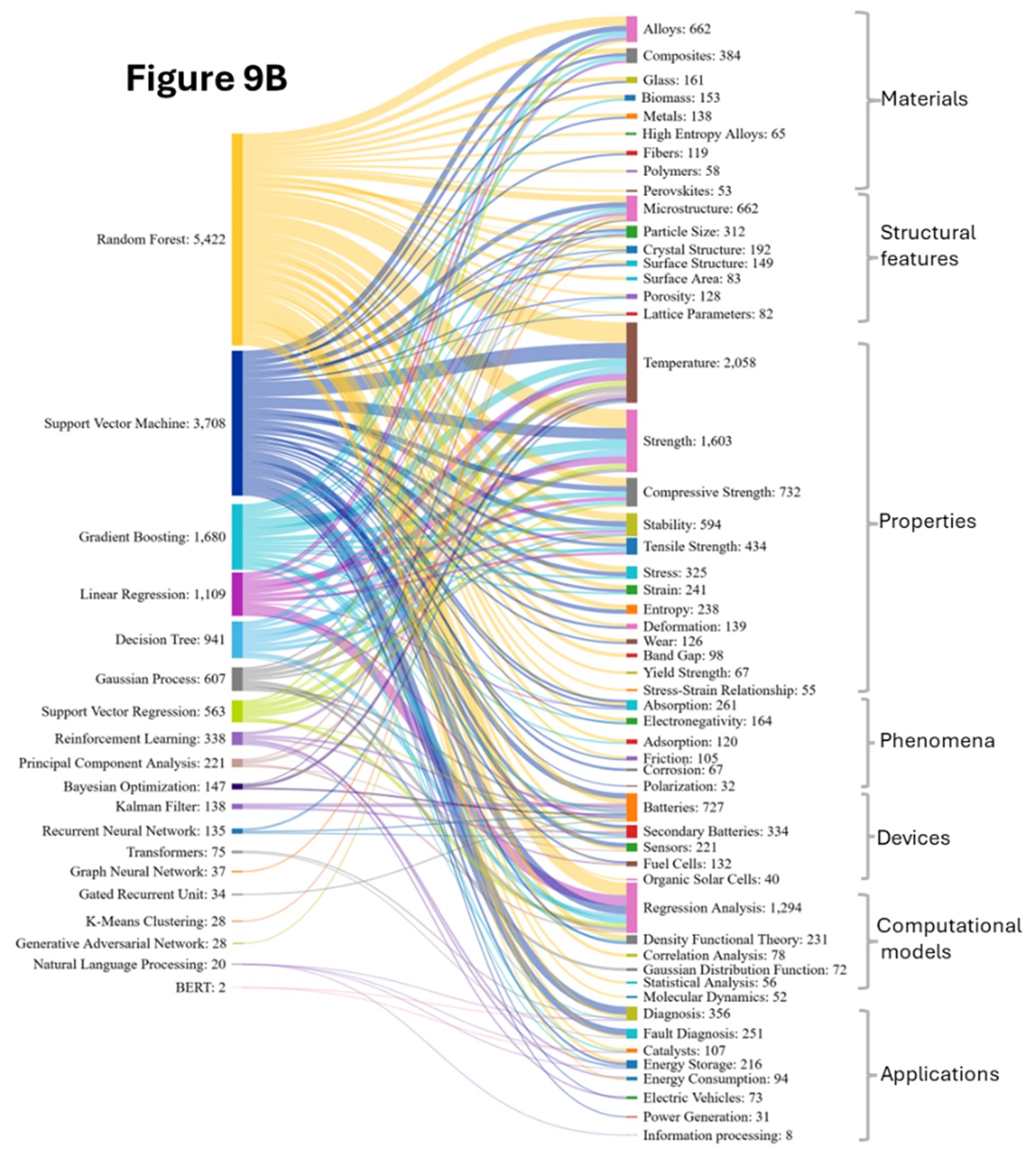
RFモデルは、あらゆる概念領域で広く使用され、配布されています。GBMモデルと共に、非線形関係をモデル化し、混合データタイプを処理する能力により、複雑で不均一な材料との強い共起を示します。これらは、マトリックスと強化材間の複雑な相互作用を捉えることによって、異種複合材料、機械的特性の予測、および故障解析によく使用されます。
これらは合金と共存しており、RFは合金組成の非線形関係をマッピングし、高エントロピー合金の設計、析出強化の予測、熱処理の最適化に役立てられています。GBは、降伏強度や耐食性の最適化などの精密な特性調整に適用される機会が増えている。
SVMは、構造と特性の関係が明確に定義されている材料でより頻繁に使用されます。このタイプのモデルは、固定次元の特徴ベクトルを使用して合金の種類としきい値を分類するのに効果的です。温度依存特性も非線形パターンに従うことが多く、組成、処理履歴、環境条件に依存しますが、ツリーベースの方法と SVMはこれを効果的に捉えます。
微細構造のような構造的特徴については、複雑な画像から特徴を特定し、粒界、相、欠陥を分類し、結晶構造を予測するためにアンサンブルモデルが採用されており、多くの場合、対称性を考慮したモデルを必要とする分類問題として扱われます。原子レベルからマクロレベルにまで及ぶ表面特性には、表面エネルギーと反応性の複雑なパターンが関係しています。これらのアプリケーションでは、画像データの前処理、マルチスケール特徴の抽出、対称性と周期性のエンコーディングが要求され、特に触媒作用、腐食、接着の研究では、分子モデリングとの統合が必要です。
応用分野は大幅に拡大し、バッテリー研究は飛躍的な成長を見せています。図9Aおよび図9Bは、RFが電気化学プロセスと強い相関関係を持ち、バッテリー容量の予測、電極材料の選択、および時間依存プロセスのための複雑な相互作用を扱っていることを確認しています。
2020年から2024年にかけて、エネルギー関連の応用分野(エネルギー貯蔵や発電)の台頭は、この分野の多様化を示しています。Long-Short Term Memory(LSTM)は、バッテリーの劣化予測や充放電サイクル性能の予測に不可欠な時間的ダイナミクスを捉えることができます。さらに新たに注目されている相関として、強化学習(RL)があり、これは充電プロトコルや材料使用の最適化が可能であり、バッテリーマネジメントシステムにも応用できます。カルマンフィルターは、バッテリーや二次電池においても利用されており、加工中の材料状態を追跡し、バッテリーの健全性の推定や残存寿命の予測に活用されています。
トランスフォーマーは、科学文献から合成手順や材料特性を抽出し、複雑な材料記述における長距離依存関係を捉えるために利用されています。畳み込みニューラルネットワーク(CNN)やGANは、2D/3D構造からの特徴抽出を自動化し、特性予測やパターン認識を支援します。強力である一方で、これらはより多くのデータと計算資源を必要とし、解釈性も低いため、従来型のモデルを置き換えるというより補完する役割を果たしています。NNは画像ベースの解析や生成的設計での利用が増えていますが、従来の手法は限られたデータセットにおける組成-特性マッピングで優位性を維持しています。このため、ニューラルネットワークと従来のモデルが組み合わせて用いられることが多くなっています。さらに、対称性や物理的制約を組み込んだ材料特化型CNNアーキテクチャが開発されつつあり、原子・分子構造に対してはGNNが注目を集めています。
材料科学における物質
CASに収載された物質の分類に立ち返り、これらの物質に関連する材料科学分野での出版件数を分析しました(図10参照)。
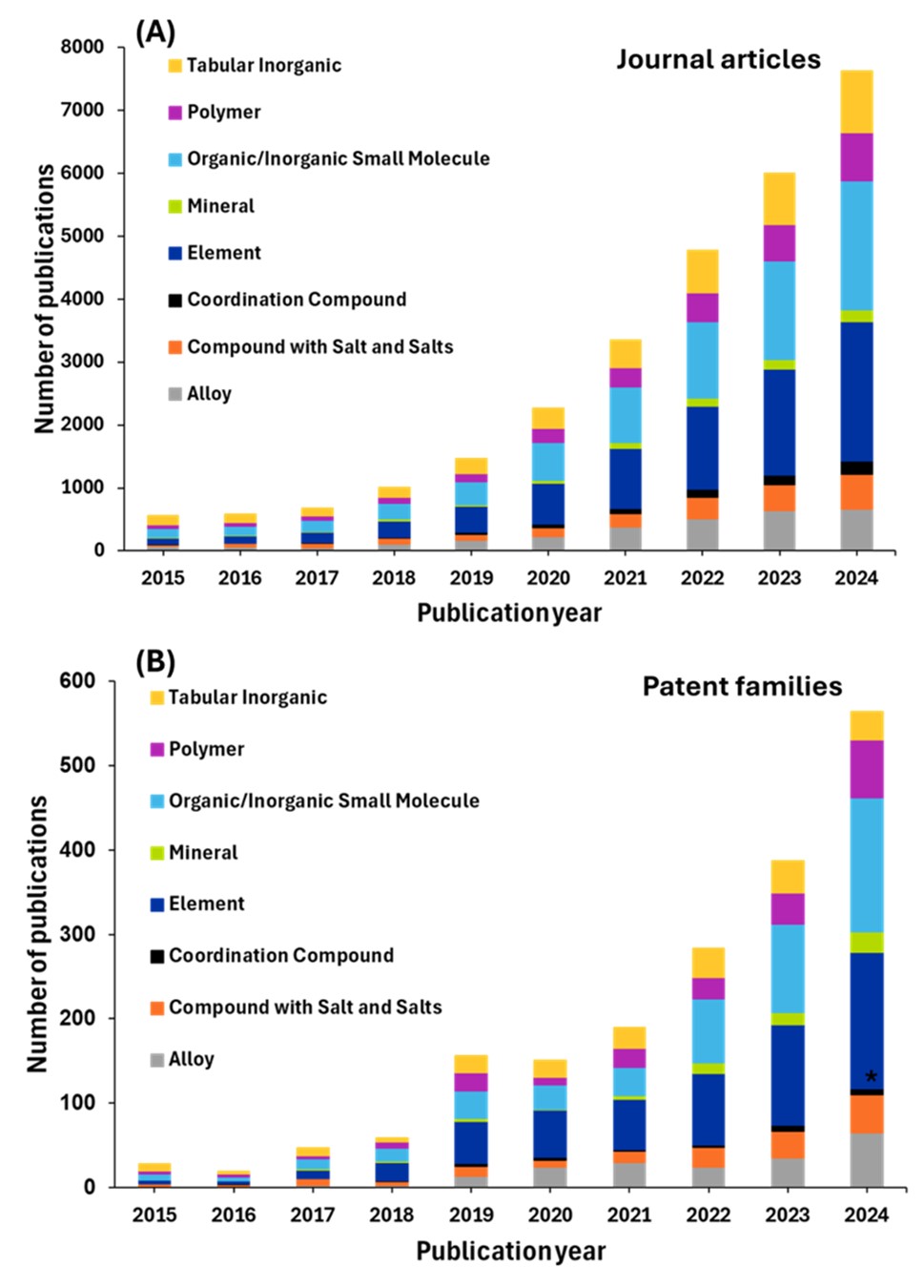
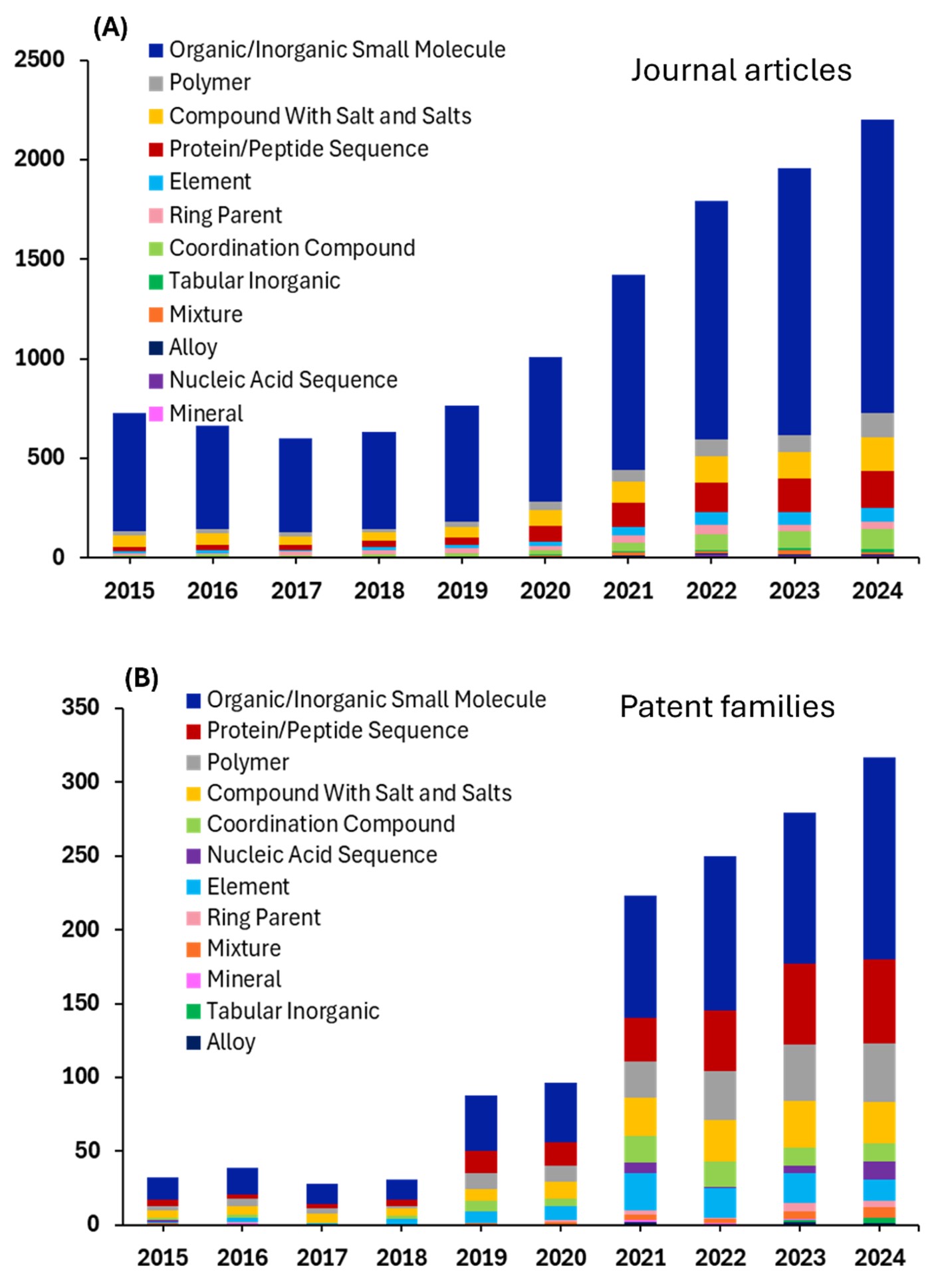
AIを活用した研究における有機/無機小分子の優位性は、ポリマーのような大規模で複雑な系に比べ、計算コストの面で小さな構造を扱う際の計算上の利点とデータの豊富さを反映しています。およそ6,500件のジャーナル論文が存在し、このカテゴリーは数十年にわたって蓄積されてきた化学データベースの恩恵を受けています。
小分子は、分子記述子、フィンガープリント、グラフベースの表現を使用してその資産、所有物、特性を効果的にエンコードできるため、MLアプローチに特に適しています。この分野の研究量が多いことは、製薬・化学業界が創薬、触媒設計、分子特性予測のためのAIに多額の投資をしていることを示しています。
Elementsは、約5,500件の論文で2位にランクされており、広範なデータベースと構造の比較的単純な性質の恩恵を受け、AIによる特性予測や材料発見の理想的な候補となっています。
板状無機材料は、約4,500件の学術論文が存在し、AIの応用が大きく進んでいる分野です。これらの材料(セラミック、酸化物、その他の構造化無機化合物を含む)は、効果的な機械学習に必要な大規模なデータセットを提供する結晶学データベースと体系的な特性測定の恩恵を受けています。これらの材料の構造化された性質により、結晶構造、組成、結合特性に基づいた一貫した特徴量エンジニアリングが可能になります。この分野がAI研究で顕著な存在感を示す背景には、エネルギー貯蔵、触媒、電子・磁気応用に向けた新規機能性材料の発見に材料科学コミュニティが注力していることが反映されていると考えられます。
ポリマー研究では、約1,800件のジャーナル論文でAIの採用が中程度であることが示されていますが、ポリマーの産業的重要性を考えると、この数字は低いように思われるかもしれません。これは、複雑な鎖構造、分子量分布、加工依存性といった特性を含む、ポリマーがAI応用にもたらす特有の課題を反映していると考えられます。しかし、研究量の増加は、AIをポリマーの特性予測、合成、加工最適化に応用する成功が拡大していることを示唆しています。
私たちの分析から得られたもう一つの重要な発見は、パテントファミリーがすべての材料科学カテゴリーにわたるジャーナル論文のほんの一部にしか相当しないということです。ジャーナル数と特許数の乖離は、材料科学におけるAI研究の多くが基礎段階または探索段階にとどまっており、学術的な発見と商業段階での特許保護に値する実用的な応用との間には大きなタイムラグがあることを示唆しています。
特許数が比較的少ないのは、AIによる材料の発見を商業的に実現可能な技術に変換するという課題を反映している可能性もあります。この分野におけるAIアプリケーションの多くは、すぐに特許を取得できる発明ではなく、特性の予測と基本的な理解に重点を置いているためです。さまざまな材料タイプで一貫した比率は、学術から商業への翻訳の課題が特定の材料クラスに固有のものではなく、材料科学全体で共通していることを示しています。
プロセス管理におけるAI
AIは、よりスマートで、より速く、より適応性の高い意思決定を可能にすることで、プロセス管理を変革しています。この分野におけるAIの役割を分析すると、自動化、予測分析、およびリアルタイムの最適化が、業界全体でオペレーショナルエクセレンスをどのように促進できるかがわかります(図11を参照)。
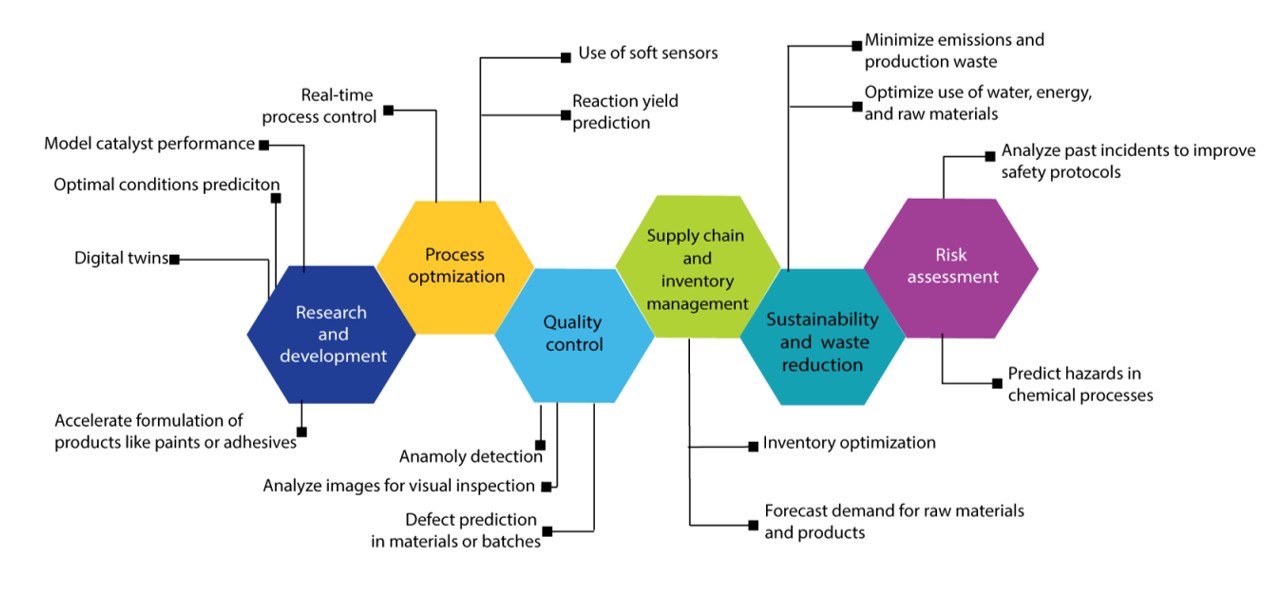
AIを活用した最適化は、積層造形、石油化学業界、プラスチック加工、冶金、フローケミストリー、触媒プロセス、創薬および合成で広く使用されています。一般的に使用されるモデルには、応答曲面法(RSM)、実験計画法、ANN、ハイブリッドモデル、PINN、LLM、強化学習アプローチなどのML技術があります。予測モデリングをリアルタイムの意思決定と自動化に拡張している他のテクノロジーをいくつか見てみましょう。
- リアルタイムモニタリング:これらのシステムは、MLを使用してストリーミングデータを分析し、パターン、トレンド、早期警告の兆候を検出し、動的予測とプロアクティブな意思決定を容易にします。主なイノベーションには、リアルタイム入力に基づいてパラメータが自動的に調整される自律的意思決定、故障が発生する前に故障を予測する予知保全、変化する状況に適応する自己改善モデルなどがあります。さらに、リアルタイムのデータ視覚化とインテリジェントな警告システムは、オペレーターがライブプロセスデータの操作方法を変革しています。このような進歩は、自動クロマトグラフィーシステムや医薬品製造における薬物反応モニタリングなど、様々な産業分野で応用されています。また、ポリマー製造における資産最適化、廃棄物管理における固形廃棄物分析、環境モニタリング、大規模水素製造におけるエネルギー・資源管理、老朽化したインフラにおけるクラウドベースのエネルギー管理などにも利用されています。
- ソフトセンサー:物理センサーからのリアルタイムデータを使用して、直接測定することがが困難またはコストがかかる変数を推定するために、AIと統計モデルを活用します。これらは、バイオプロセスの監視、廃水および空気の質の監視など、さまざまな業界で広く適用されています。化学プロセス制御では、ソフトセンサーを使用して、複雑な硫化鉱石の浮遊、異性化、反応蒸留、ガソリン混合を監視します。
- デジタルツイン:これらの革新技術は物理システムの仮想複製であり、AI統合により急速に進化を遂げ、リアルタイムの最適化、予測分析、自律的な運用を実現します。AIは、過去のデータとリアルタイムデータから学習して将来の状態をシミュレートし、異常を検出し、障害を予測することで、デジタルツインを静的なモデルから回復力のある自己最適化システムへと変換します。製造業では、AIを活用したデジタルツインにより、機器の故障を予測し、生産プロセスを最適化し、センサーと画像を使用して品質の問題を検出します。ヘルスケアでは、患者の状態をシミュレートし、個別化医療をサポートし、疾患をモデル化し、臨床試験のシミュレーションを行い、免疫療法を最適化します。環境と持続可能性の分野では、AI を活用したデジタルツインが地質学的炭素貯留、鉱石廃棄物の処理、リソース、資源、物資、供給源管理に応用されています。また、材料科学もサポートしており、自動検出、欠陥分析、逆分子設計が可能になります。
科学研究におけるAI活用の課題
AIは明らかにあらゆる科学的な研究分野に多くのプラスの貢献を果たしており、今後も進歩し続けるでしょう。しかし、これらの革新には、AIが科学でその潜在能力を最大限に発揮できるようにするために、研究者やデータサイエンティストが取り組まなければならない課題があります。最も差し迫った課題には次のようなものがあります。
- データのプライバシーとセキュリティ:AIのトレーニングと運用には大量の機密データが必要となるため、データのプライバシーとセキュリティを確保することはAIの実装における最大の課題の1つです。機密情報が適切な許可なく収集され、使用されたり、AIシステムから機密情報が漏洩したり盗まれたりすると、問題が発生します。科学的データセットには、未発表の実験結果、新しい化合物構造、大きな競争上の優位性をもたらす独自の合成方法などが含まれている場合があります。研究者がクラウドベースのAIプラットフォームを利用したり、共同研究環境に参加したりする際、知的財産の露出に関する重大なリスクに直面します。リスクに対抗するため、一部の企業は顧客情報を保護し信頼を維持するための安全策を講じており、新興企業は外部のAI脅威から身を守るためのニッチ市場を見つけています。
- データの品質とバイアス:データセットは、AIモデルを通じて伝播する可能性のある体系的なバイアスの影響を受けることが多く、予測の歪みを招き、既存の研究の不公平性を強化する可能性があります。成功した反応が過大評価され、失敗した実験が過少に報告されるなど、公開された反応データの歴史的偏りは、特に無機材料において、MLモデルが新しい化学領域を探索する能力を著しく損なう可能性があります。この「出版バイアス」は、AIシステムがすでによく研究されているものと同様の化合物を優先的に推奨するという自己強化サイクルを生み出します。生成AIモデルは、既存のデータを操作し、実際の証拠を犠牲にして顧客の要求を満たすためにハルシネーションを起こす可能性があるため、さらなる懸念が生じます。
- 透明性:これらのモデルの「ブラックボックス」的性質は、予測の背後にある推論を不明瞭にし、研究者がその信頼性を評価したり潜在的な障害モードを特定したりすることを困難にします。創薬における説明可能なAI手法に関するレビューは、複雑なモデルにおける解釈可能性の欠如が、医薬化学者間の信頼を損ない、医薬品開発におけるAI主導の意思決定の規制当局による承認を妨げ得ることを浮き彫りにしました。この課題は、特に高次元の化学表現を扱うグラフニューラルネットワークやトランスフォーマーモデルにおいて顕著であり、入力特徴と予測との関係が高度に非線形となります。
- 自動化と人間の専門知識のバランス:AIシステムは膨大なデータセットを処理し、人間の認知能力を超えたパターンを識別することができますが、経験豊富な科学者が研究問題にもたらす直感、創造性、そして文脈的理解は欠けています。これにより、基礎的な研究スキルと概念的理解が欠如した科学者の世代が生まれる可能性があります。逆に、AIによる結論が直感と矛盾する場合、「アルゴリズム嫌悪」につながることもあります。
AIモデルと科学研究の将来
AIは科学的探究においてますます重要性を増し、その革新的な能力はすでにバイオメディカルや材料科学などの分野で実現されています。CASコンテンツコレクションの分析が示すように、困難な研究課題に対して常に新たな応用、モデル、手法が適用されています。創薬、疾患診断、材料開発など、AI技術の影響を受ける、あるいは完全に推進される分野でのブレークスルーが期待できます。
AIが単なるツールから共同研究パートナーへと進化するにつれ、逆設計や自律型実験室といった新たなパラダイムが科学的手法を再定義し、自律的な発見エンジンへと向かう可能性も高まっています。しかし、特許取得率と論文発表数の比率が低いことは、特に伝統的な材料科学分野において、多くの研究が依然として学術界に留まっていることを示しています。
AIのさらなる普及には、不確実性の定量化やモデルの透明性といった技術的ソリューションを通じた適切な信頼性の調整が必要です。AI が科学に与える影響は多岐にわたり、その導入にあたってはさまざまな課題が伴うため、科学の進歩に対するAIのメリットを最大化するには、連携と可視性が鍵となります。
詳細については、当社の再版ジャーナル記事「化学におけるAI革命:材料科学と生物医学の将来を形作る」をお読みください。
本資料におけるブランド名の使用および/または第三者の製品・サービスへの言及は、教育目的のみを意図したものであり、CASまたは米国化学会による推奨を意味するものではなく、また言及されていない類似のブランド、製品、サービスに対する差別を意味するものではありません。




